How big is your BigQuery data?
It is good to know how big is your data. Especially if you have to pay for the storage. See below 3 ways on how to keep track of your data size.
BigQuery gives us a lot of flexibility and very low entry barrier. Thanks to a simple interface, no initial setup requirements, and pay-as-you-go model it is easy to start experimenting with the data - for example using public datasets.
But there is always a cost - for BigQuery it is $5 for every terabyte of query data (the first 1 TB per month is free), and $0.1 to $0.2 for storage (the first 10 GB is free each month). It seems not much but nowadays it's not a challenge to generate significant bill (or drain your free trial credits). Example? Python Package Index (PyPI) dataset provides download statistics for all package downloads from the Python Package Index (PyPI). It is public data, stored in BiqQuery as a public dataset - and it's the biggest table is over 170TB in size:
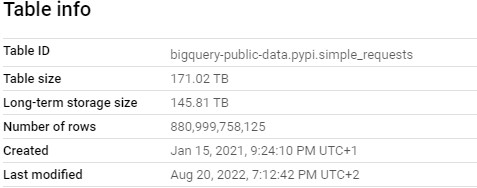
But what about other tables? How can we check it? Let's dive in.
BigQuery exposes a lot of useful information in information schema tables. One example is __TABLES__ table which unsurprisingly holds some information about the tables in a specific dataset.
The query result gives us not only information about the table size in bytes, which we can continently convert but also a number of rows and other information - and the PyPi dataset at the time of writing this post has over 300TB of data and over a trillion of rows!
But is there any other way to get this info? Naturally...
Cloud Monitoring is a super helpful tool that allows you to investigate what's happening with your cloud infrastructure. For instance, you can explore information about your BigQuery datasets in metrics explorer - check out the template: sample template

This option gives you the best flexibility, by using a dedicated client library. You can install it using pip:
pip install google-cloud-bigquery
The below script allow you to download dataset information for multiple projects and save it to separate .json files - you just need to have appropriate permissions in respective projects.
There are many ways to find out how much data is stored in a specific BigQuery table, dataset or project. Which one to use? It depends on the use case.
Quering __TABLES__ view is convenient when you're using mostly the web GUI or you want to use this data-size information in wider context (i.e. to drop large tables), and you could easily build a dashboard in Data Studio or other BI tool based on the __TABLES__ view.
If your needs are limited you can use Cloud Monitoring to build a quick dashboard that will satisfy your needs.
Last but not least using Python script gives you the most flexibility, but it requires more work to visualize it or share results with a wider audience.
But there is always a cost - for BigQuery it is $5 for every terabyte of query data (the first 1 TB per month is free), and $0.1 to $0.2 for storage (the first 10 GB is free each month). It seems not much but nowadays it's not a challenge to generate significant bill (or drain your free trial credits). Example? Python Package Index (PyPI) dataset provides download statistics for all package downloads from the Python Package Index (PyPI). It is public data, stored in BiqQuery as a public dataset - and it's the biggest table is over 170TB in size:
But what about other tables? How can we check it? Let's dive in.
1. Querying the __TABLES__ schema.
BigQuery exposes a lot of useful information in information schema tables. One example is __TABLES__ table which unsurprisingly holds some information about the tables in a specific dataset.
SELECT
project_id,
dataset_id,
table_id,
TIMESTAMP_MILLIS(creation_time) AS creation_time,
TIMESTAMP_MILLIS(last_modified_time) AS last_modified_time,
row_count,
size_bytes,
size_bytes/POW(2,30) AS size_gb,
size_bytes/POW(2,40) AS size_tb
FROM
`bigquery-public-data.pypi.__TABLES__`
The query result gives us not only information about the table size in bytes, which we can continently convert but also a number of rows and other information - and the PyPi dataset at the time of writing this post has over 300TB of data and over a trillion of rows!
But is there any other way to get this info? Naturally...
2. Using Cloud Monitoring
Cloud Monitoring is a super helpful tool that allows you to investigate what's happening with your cloud infrastructure. For instance, you can explore information about your BigQuery datasets in metrics explorer - check out the template: sample template
3. Using Python script
This option gives you the best flexibility, by using a dedicated client library. You can install it using pip:
pip install google-cloud-bigquery
The below script allow you to download dataset information for multiple projects and save it to separate .json files - you just need to have appropriate permissions in respective projects.
import datetime
import logging
import json
from google.cloud import bigquery
projects = [
'your-project(s)-name(s)',
]
def get_bq_metadata(project):
"""Gets metadata from public BigQuery datasets"""
metadata = []
client = bigquery.Client(project=project)
datasets = client.list_datasets()
for dataset in datasets:
dataset_id = dataset.dataset_id
dataset_ref = client.get_dataset(dataset_id)
tables = client.list_tables(dataset_id)
for table in tables:
full_table_id = table.full_table_id.replace(':', '.')
table_ref = client.get_table(full_table_id)
item = {'dataset_id': dataset_id,
'project_id': project,
'table_id': table_ref.table_id,
'dataset_description': dataset_ref.description,
'table_modified': table_ref.modified.strftime("%Y-%m-%d %H:%M:%S"),
'table_created': table_ref.created.strftime("%Y-%m-%d %H:%M:%S"),
'table_description': table_ref.description,
'table_num_bytes': table_ref.num_bytes,
'table_num_rows': table_ref.num_rows,
'table_partitioning_type': table_ref.partitioning_type,
'table_type': table_ref.table_type,
}
metadata.append(item)
return metadata
if __name__ == '__main__':
for project in projects:
json_object = json.dumps(get_bq_metadata(project), indent=4)
with open(f"{project}_bq_data.json", "w") as outfile:
outfile.write(json_object)
Summary
There are many ways to find out how much data is stored in a specific BigQuery table, dataset or project. Which one to use? It depends on the use case.
Quering __TABLES__ view is convenient when you're using mostly the web GUI or you want to use this data-size information in wider context (i.e. to drop large tables), and you could easily build a dashboard in Data Studio or other BI tool based on the __TABLES__ view.
If your needs are limited you can use Cloud Monitoring to build a quick dashboard that will satisfy your needs.
Last but not least using Python script gives you the most flexibility, but it requires more work to visualize it or share results with a wider audience.
stay curious.